Most healthcare tech AI deployments don't fail because the model is wrong. They fail because no one can prove the model is right.
Agentic AI is advancing rapidly in healthcare technology. According to McKinsey, these systems can now manage complex workflows end-to-end — from prior authorizations to clinical decision support — that previously required hours of manual effort. A new category of AI workers capable of reasoning, planning, and acting independently is genuinely arriving in hospitals and health systems.
But the scale is stalling. Not because the technology isn't ready. Because the trust infrastructure isn't. IBM's research with life sciences and healthcare tech leaders found that when asked about the biggest barriers to adopting agentic AI, organizations consistently pointed to the same set of concerns: data privacy, accuracy and hallucination risk, unclear accountability, and the absence of governance frameworks that make autonomous decisions auditable. Nearly half reported gaps in their understanding of how to deploy these systems responsibly.
The organizations that are getting this right aren't waiting for the model to improve. They're building the three things that make AI trustworthy in a clinical environment — what we call the trust trifecta: Observability (full visibility into what the system is doing), Traceability (every output linked back to its source), and Trust-but-Verify (continuous evaluation that doesn't require ground truth to exist).
Pillar 1: Observability — Make Every AI Decision Visible Before Something Goes Wrong
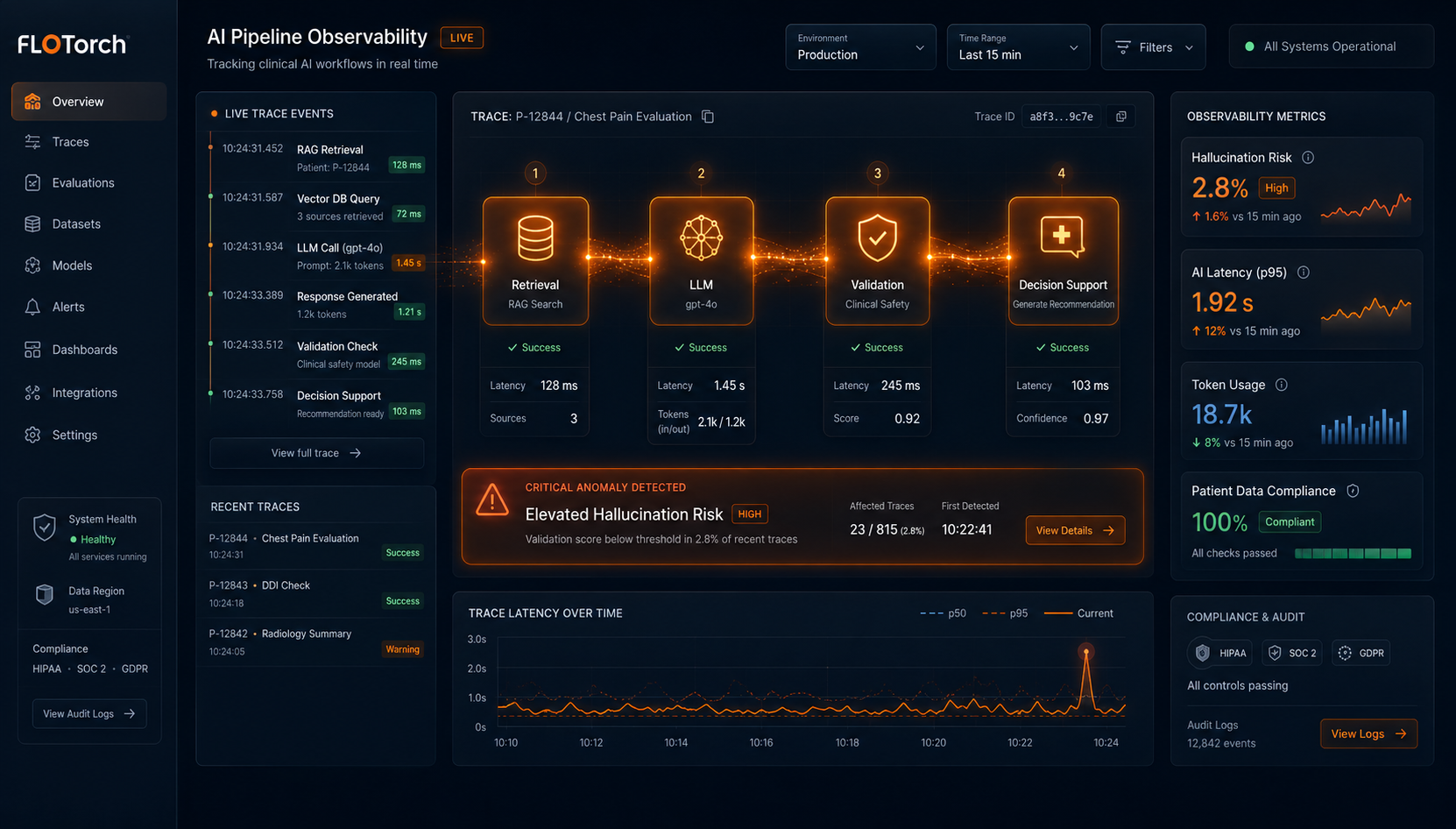
Agentic systems chain together multiple steps: LLM calls, retrieval lookups, tool invocations, and branching logic. In a clinical workflow, a wrong output at step three can propagate silently to step seven. By the time it surfaces, tracing what happened requires forensic work — if it's possible at all.
GE HealthCare's research on agentic systems is direct on this: trust and safety require specific safeguards beyond standard data privacy measures. A human-in-the-loop strategy for clinical validation, regular audits, and independent validation loops are prerequisites — not optional governance layers.
IBM frames it similarly: accountability requires explicit explainability and observability requirements built in from the start, alongside well-defined review workflows and open decision logs that anyone can inspect.
In practice, this means:
- Trace-level logging of every agent action, retrieval step, and model invocation — capturing not just inputs and outputs, but the reasoning chain between them.
- Real-time cost and latency tracking per query, which is vital for capacity planning and justification of cloud/on-premise resource allocation, so operational teams can detect model drift or performance degradation before it reaches care workflows.
- Audit-ready logs that satisfy HIPAA requirements, comply with compliance review without manual reconstruction, and integrate with existing Security Information and Event Management (SIEM) systems for unified security monitoring and compliance alerting for events like unexpected data access or high-volume query anomalies.
Without this, "the AI recommended it" is not a defensible answer in a clinical or regulatory review. With it, every decision has a verifiable paper trail — and that paper trail is what earns clinician confidence over time.
Pillar 2: Traceability — Every AI Output Needs a Source That Holds Up
Clinicians accept AI recommendations when those recommendations come with evidence. A suggestion without a citation — or one that traces back to a poorly indexed or incorrectly normalized knowledge base — creates more liability than it resolves.
McKinsey notes that trust in agentic systems requires strategically placed checkpoints where a person can validate outputs before they navigate to the next step of a workflow. The model is only as trustworthy as the information pipeline feeding it.
This is where production healthcare tech RAG systems frequently break down — not at the LLM layer, but at the retrieval layer underneath it. In a benchmarking study FloTorch conducted for a leading cancer research center, a single infrastructure issue — Unicode inconsistencies in the clinical knowledge base — degraded retrieval quality by up to 40 NDCG@1 points across multiple embedding models. The models themselves were performing correctly. The pipeline was not.
The fix required no model changes: canonical text normalization (Unicode standardization, symbol cleanup, spacing normalization) restored retrieval accuracy and, in some cases, improved it significantly above the pre-deployment baseline. The lesson was straightforward: if you can't guarantee what gets retrieved, you can't guarantee what the system says. Traceability begins at the data layer, not at the output layer.
The IS perspective requires a discussion on interoperability standards. Recommendations must explicitly include tracing of data ingestion and output against FHIR and HL7 standards, and detailing how the agentic system attributes sources back to the authoritative system of record (e.g., Epic, Cerner) via standard APIs.
For Data Science, Data Engineering, and healthcare tech teams, this translates directly: benchmark your retrieval stack with the same rigor you apply to model selection. Test chunking strategies, embedding models, and normalization pipelines on your own data before committing to a production architecture.

Pillar 3: Trust-but-Verify — You Can't Wait for a Ground Truth That Doesn't Exist
The hardest evaluation problem in clinical AI is that there is often nothing to evaluate against. Domain-specific ground truth — expert-annotated question-answer pairs built on oncology protocols, drug interaction databases, or imaging guidelines — takes months to produce, is expensive, and is incomplete by design. You can't annotate your way to production confidence in a reasonable timeframe.
IBM's framework for agentic governance addresses this directly: human-in-the-loop oversight during early adoption is essential, but the goal is a system where, as models demonstrate consistent high-quality performance over time, the burden on human validators decreases. The evaluation architecture has to be built to scale.
LLM-as-a-Judge is the mechanism that makes this possible. Rather than requiring full expert annotation, a judge model evaluates outputs against defined clinical criteria — factuality, internal consistency, evidence grounding — at the speed of production queries. FloTorch used this approach in the cancer research center study: with no existing ground truth dataset, LLM-as-a-Judge generated pseudo-ground-truth labels that enabled fair, reproducible cross-model and cross-cloud comparison across 2,000+ clinical queries. The discussion on LLM-as-a-Judge should be framed as an MLOps requirement, calling for automated pipelines for continuous deployment (CI/CD) and monitoring that use the LLM-as-a-Judge feedback loop to trigger automated model retraining or flag outputs for manual human review.
Used with appropriate rigor — clear evaluation rubrics, structured reasoning, and validation hooks — LLM-as-a-Judge doesn't replace human review. It surfaces what outputs actually need it. The result is a trust feedback loop: the system identifies anomalies, flags low-confidence outputs, and builds an evidence base that human reviewers can refine over time.
Security, Compliance, and Data Governance
This is the most critical missing area for a Health Information Technology (HIT) provider, extending far beyond the current mention of HIPAA.
- PHI Security Model: Detail how Protected Health Information (PHI) is managed across all agent components: the vector database, LLM memory/context window, and audit logs. This includes detailed requirements for end-to-end encryption and tokenization strategies.
- Access Control (RBAC): Detail the necessity of Role-Based Access Control (RBAC) to restrict tool invocation and data access based on the user's clinical role to ensure least-privilege principles are enforced.
- Regulatory Landscape: Expand its compliance scope beyond general HIPAA requirements to include state-level data residency requirements and guidance on the FDA's regulatory path for Agentic AI used in clinical decision support.
Total Cost of Ownership (TCO) and ROI Justification
IS leadership must justify the investment.
- Cost Modeling: Outline how to calculate the TCO for agentic AI, including infrastructure costs (inference APIs, GPU/TPU consumption), human-in-the-loop oversight costs, and licensing and maintenance for specialized tooling.
- Operational Efficiency Metrics: Tie the "trust trifecta" directly to ROI. For instance, how does better Observability translate into reduced mean time to resolution (MTTR) for system incidents?
Enterprise Integration and Architecture
This addresses the practicality of fitting new technology into complex hospital IT environments.
- Reference Architecture: Include high-level architecture discussions on integrating agentic systems with the existing IT stack (EHR, PACS, LIS, SIEM).
- API Management and Scalability: Discuss how the agent services are deployed and managed using enterprise API gateways to handle the scale, authentication, and throttling required by high-volume clinical workflows.
Change Management and Staff Enablement
The IS team is responsible for the technical rollout and support.
- IT Staff Training: Recommend training programs focused on troubleshooting, monitoring, and maintaining the agentic architecture for IT staff, who need to understand the RAG pipeline and MLOps processes.
- System Documentation: Emphasize the need for comprehensive documentation for both technical teams (API specs, deployment guides) and clinical teams (workflow guides, troubleshooting steps) to ensure reliable operations and adoption.

What About Patient-Facing Trust?
The observability, traceability, and evaluation framework above is the infrastructure layer. But clinicians and systems leaders also have a trust problem with patients.
Providertech's analysis of patient trust in AI cites Deloitte research showing 80% of consumers want to be informed about how their healthcare provider is using AI — and roughly 65% are supportive of its use when they are. The breakdown of trust happens not because patients oppose AI, but because they discover it without prior notification.
The practical takeaway: the same transparency principles that build clinician trust — explainable outputs, auditable decisions, human oversight at checkpoints — also map to patient communication strategy. Transparent disclosure, proactive communication, and clear explanations of where AI is involved and what it does are not optional governance tasks. They are the adoption mechanism.
The Framework That Moves AI from Experiment to Production
McKinsey puts it clearly: agentic AI allows a spectrum of autonomy, and in high-stakes contexts like healthcare, a strategically placed human in the loop is always a critical safeguard. Increased autonomy doesn't reduce the need for governance — it increases it.
GE HealthCare frames the opportunity well: the intelligence currently trapped in healthcare data has the potential to scale multi-disciplinary reasoning and process automation — but only if the systems harnessing it are built with the evidence standards that clinical environments require.
The organizations closing the gap between AI experimentation and production aren't doing it by shipping more powerful models. They're doing it by building the evaluation infrastructure, retrieval governance, and observability tooling that make every model decision defensible.
For Data Science, Data Engineering, and Healthcare IT teams evaluating where to start:
Instrument your pipelines before deployment, not after the first incident.
Benchmark the full stack — embedding models, chunking strategies, normalization pipelines, cloud provider cost, and latency tradeoffs — on your own clinical data.
Build evaluation into the architecture. LLM-as-a-Judge should be designed as an ongoing infrastructure, not a one-time audit.
Make the audit trail a first-class output. In a regulated domain, the evidence that a decision was made responsibly carries as much weight as the decision itself.
Trust in agentic AI isn't something you earn once. It's something you build continuously — through the infrastructure that makes every decision visible, every output traceable, and every evaluation reproducible.
FloTorch is an enterprise platform for building, evaluating, and scaling agentic AI workflows. We've worked with healthcare tech and life sciences organizations to benchmark retrieval stacks, run LLM evaluations across clinical queries, and build the observability infrastructure that production-grade AI requires. Read our Healthcare AI RAG Benchmarking Case Study, explore FloTorch, or book a demo.