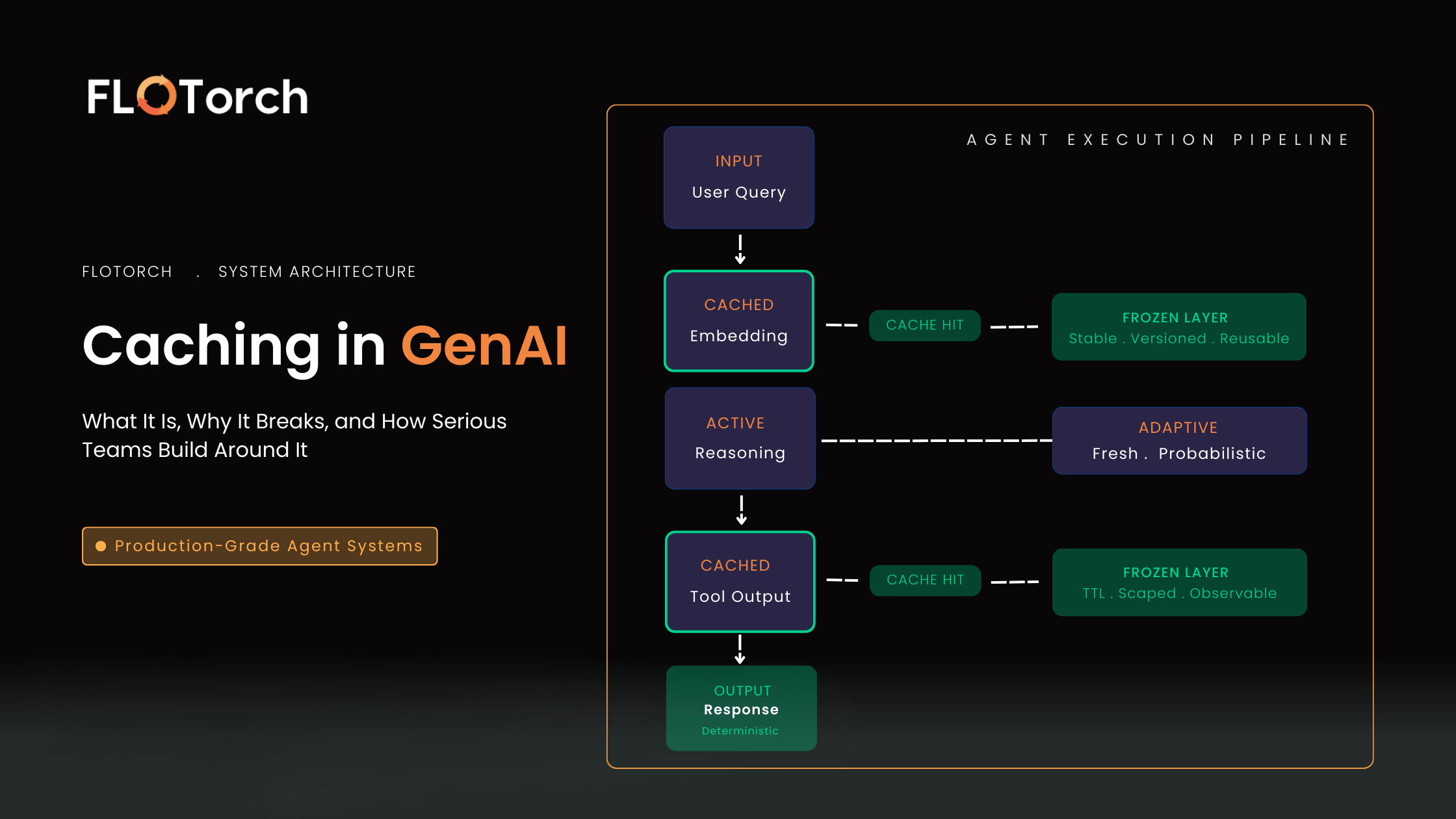
Most GenAI teams discover caching the same way: their cloud bill spikes, latency creeps up, and suddenly a "simple agent workflow" is making hundreds of model calls per hour. Their first instinct is to add a Redis layer and move on.
That instinct is understandable. It's also wrong.
Caching in agent-based GenAI systems isn't a performance optimization you bolt on after the fact. It's an architectural decision that shapes how reliably your agents behave, how predictably they cost money, and whether you can actually debug them when things go wrong. Get it right early and you have a system you can govern. Get it wrong and you have a system that occasionally works — and you don't know why.
This article covers caching from the ground up: what's actually worth caching, how each layer breaks in production, concrete strategies for each, and a decision framework for teams building serious systems.
Why Traditional Caching Intuition Breaks in GenAI
In conventional software, caching is conceptually simple: same input, same output, safe to store and reuse. A database query, an API response, a rendered template — deterministic all the way down.
GenAI breaks every one of those assumptions:
- Outputs are probabilistic. The same prompt at temperature > 0 produces different responses each time.
- Context windows are dynamic. Two calls with identical prompts but different conversation histories are fundamentally different inputs.
- Agents reason over intermediate states. A cached response from step 3 of a workflow may be invalid if step 2 produced a different result than last time.
- "Similar" inputs may genuinely require different outputs. Semantic similarity is not logical equivalence.
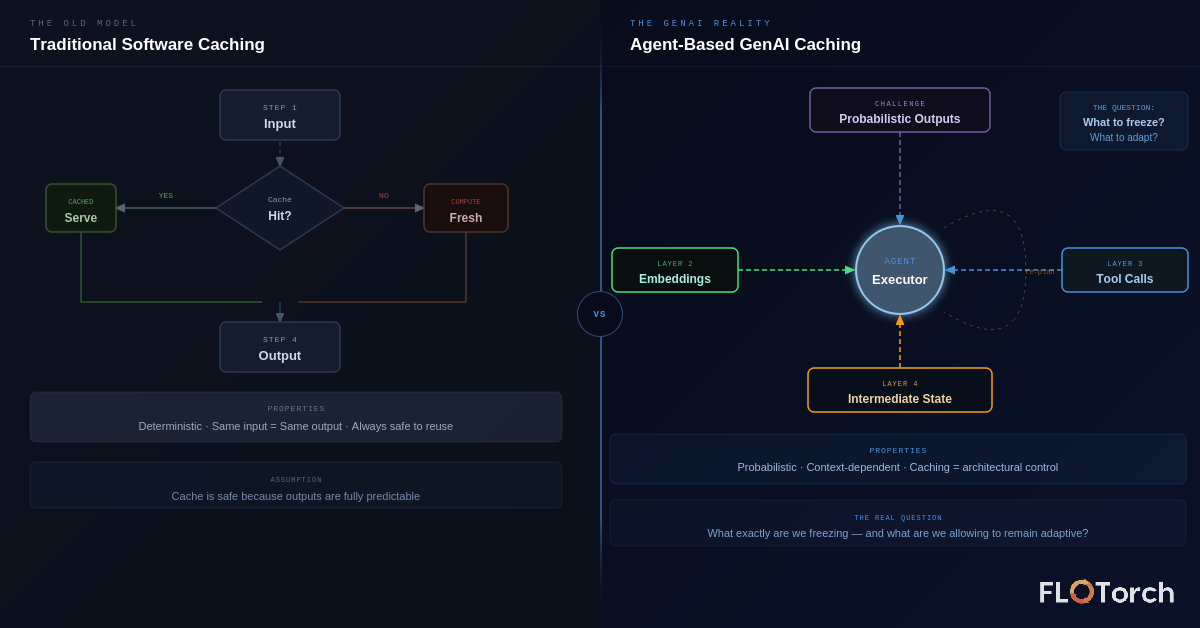
The real question isn't "Can we cache this?" It's "What exactly are we freezing — and what are we allowing to remain adaptive?"
Once you see it this way, caching stops being an optimization. It becomes a control mechanism: the architectural decision about which parts of your agent's intelligence are stable enough to reuse, and which must be recomputed fresh. FloTorch's agent-aware cache management is built on exactly this principle — caching as a behavioral guarantee, not a performance trick.
The Real Cost of Not Caching: Three Compounding Failures
1. Latency Grows Non-Linearly
Agents don't make a single model call. They plan, reflect, retry, and loop. A single uncached retrieval step that adds 800ms of latency doesn't add 800ms to your workflow — it multiplies. If that step is called by three downstream tasks that each spawn two sub-tasks, you've just added 4+ seconds of latency to your end-to-end response time from one missed cache.
In practice, teams observing production agent traces frequently find that 40–60% of total execution time is spent in steps whose outputs haven't changed since the last run.
2. Costs Become Unpredictable
Without disciplined caching, the same workflow can cost materially different amounts on different days — not because the task changed, but because intermediate states weren't preserved. Teams have reported 3–5x variance in per-run inference cost for nominally identical workflows when caching is absent.
This makes budget forecasting essentially impossible, and minor prompt changes cause inference churn that's completely invisible until the billing cycle closes.
3. You Lose Reproducibility — and With It, Governance
This is the one that kills teams slowly. If you can't replay a specific decision path, a tool call sequence, or a memory state, you can't debug agent failures with confidence. You can't run meaningful regression tests. You can't explain to a stakeholder why the agent made a particular decision last Tuesday.
Reproducibility isn't just a developer convenience — it's a governance requirement. Wherever agents make consequential decisions — financial, medical, operational — you need to prove why they behaved the way they did. Caching is the mechanism that turns "it worked once" into "we know why it works."
The Four Caching Layers: What Mature Teams Actually Cache
The interesting question isn't what can be cached — it's what should be cached at each stage of agent execution, and with what invalidation strategy. Here's a layer-by-layer breakdown.

Layer 1: Prompt–Response Caching
The most obvious layer, and also the most dangerous if implemented naively. Caching prompt–response pairs is genuinely valuable for:
- Evaluation pipelines — where determinism is the point.
- Regression test suites — you want to know if a change altered behavior.
- Fixed, templated workflows — where the prompt is effectively static.
The failure mode is version blindness. Consider this scenario:
# Naive cache key — dangerously underspecified
cache_key = hash(prompt_text)
# What it misses:
# - prompt version (v1.2 vs v1.3)
# - model version (gpt-4o vs gpt-4o-2024-08-06)
# - temperature / sampling params
# - system prompt changes
# Better cache key
cache_key = hash(prompt_text + prompt_version + model_id + str(params))Layer 2: Embedding Caching
Embedding pipelines are a major hidden cost center. In most RAG-based agent systems, the same documents are re-chunked, re-embedded, and re-scored multiple times across runs — often without any change in the underlying documents. The cost compounds fast: at $0.13/million tokens for text-embedding-3-small, a 500-document corpus re-embedded on every run adds up quickly at scale — trivial per run, significant across 10,000 evaluations.
But the subtler issue is retrieval drift. If your embedding cache doesn't invalidate correctly when source content changes, you end up with a situation where:
- The cache returns a vector for Document A based on its state from last week.
- Document A has since been updated with critical new information.
- The agent retrieves confidently, scores well, and surfaces stale content.
The fix is content-addressed caching — keying embeddings on both the document ID and a hash of the document content, so any content change automatically busts the cache for that document without requiring a full re-ingestion.
# Content-addressed embedding cache key
content_hash = sha256(document_text)
cache_key = f'embed:{doc_id}:{content_hash}:{embedding_model_version}'
# On lookup: if content_hash mismatches, re-embed and updateLayer 3: Tool Output Caching
This is where agent systems bleed the most time and money in production. Agents depend heavily on external tools — search APIs, internal databases, web crawlers, proprietary services — and those tools are slow, unreliable, and expensive. When they aren't cached:
- A flaky API causes the agent to retry, multiplying cost and latency.
- Deterministic queries get re-executed needlessly.
- Failures cascade: one tool timeout causes an agent to abandon a partially-completed plan and restart.
The key design decision for tool output caching is TTL strategy. Unlike prompt–response caches, tool outputs have real-world freshness requirements:
# TTL tiers by data volatility
TOOL_CACHE_CONFIG = {
'stock_price_api': {'ttl_seconds': 60}, # Real-time data
'weather_api': {'ttl_seconds': 1800}, # 30 min
'company_profile_api': {'ttl_seconds': 86400}, # 24 hours
'static_knowledge_db': {'ttl_seconds': 604800}, # 7 days
}Well-designed tool output caching turns brittle third-party dependencies into reliable building blocks. The agent always gets a response; the cache handles freshness; retries become rare rather than routine. FloTorch's granular cache control lets you define TTL rules, force-fresh overrides, and cache-busting policies per node — no custom code required.
Layer 4: State and Memory Caching
This is where GenAI caching gets hard — and where the stakes are highest. Agent systems generate several categories of intermediate state:
- Reasoning traces — the chain-of-thought steps an agent uses to arrive at a decision.
- Planning states — partially-constructed task plans mid-execution.
- Working memory — facts the agent has retrieved and is holding in context.
- Partial task completions — results from sub-tasks that are logically complete, even if the overall workflow isn't.
Without state caching, a network timeout or compute preemption at step 7 of a 10-step workflow means restarting from zero. With state caching, you get safe resumption:
# Checkpoint-based state caching pattern
class AgentExecutor:
def run_step(self, step_id, state):
cache_key = f'state:{self.run_id}:{step_id}:{hash(state)}'
cached = self.state_cache.get(cache_key)
if cached and not self.force_recompute:
return cached
result = self.execute(step_id, state)
self.state_cache.set(cache_key, result, ttl=3600)
return resultState caching also enables deterministic replay — the ability to take a specific run's cached execution trace and re-run it exactly, which is the foundation of any serious evaluation or audit capability. FloTorch provides cache visibility and full audit trails so every cache hit is logged, traceable, and referenceable across runs.
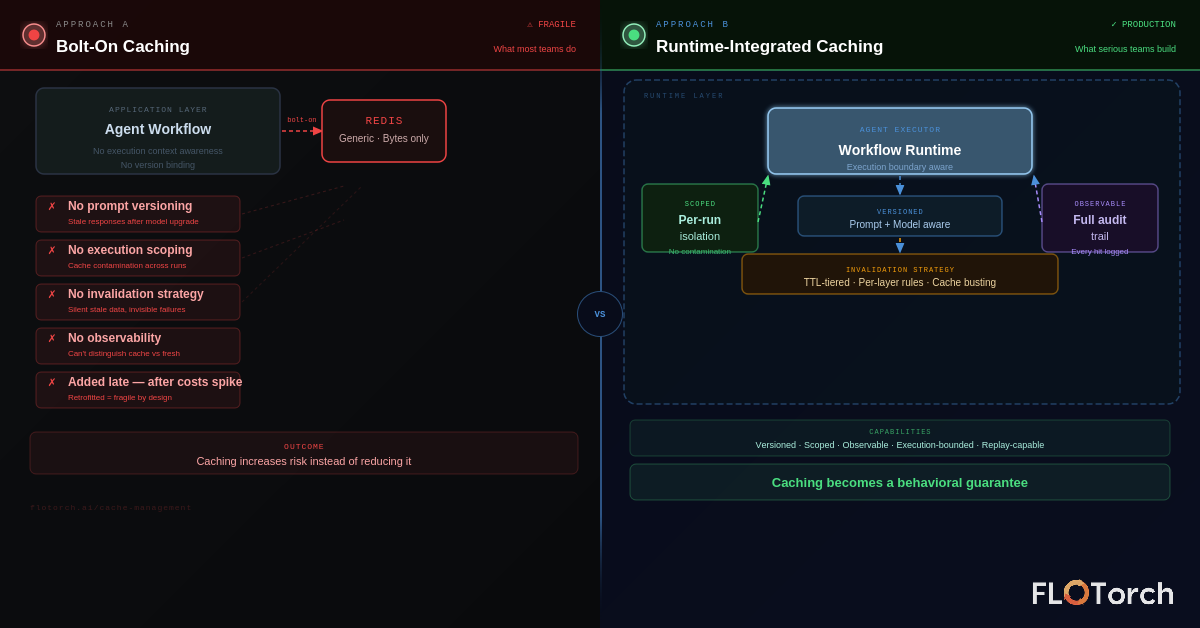
The Architectural Mistake: Why Bolting On Caching Fails
Most teams add caching late — after workflows are built, after costs spike, after debugging becomes painful. By that point, caching is retrofitted around an architecture that wasn't designed to support it, and the results are predictable:
- Inconsistent cache keys across different parts of the codebase.
- No invalidation strategy — caches grow stale, and no one knows.
- Tight coupling between prompt structure and cache key logic.
- No observability — you can't tell what was served from cache versus freshly computed.
The deeper problem is that application-layer caching — a Redis instance your code talks to directly — doesn't understand agent execution semantics. It doesn't know where one agent run ends and another begins. It can't scope caches safely to individual executions. It has no awareness of prompt versions or model versions.
Caching in production agent systems needs to be runtime-aware: it must understand execution boundaries, version context, and scope — not just store and retrieve bytes.
This means caching architecture needs to be considered at the same time as workflow architecture, not after it. The questions to answer up front:
- Which steps in this workflow are safe to cache across runs, and which must be fresh?
- What constitutes a cache key at each layer, and how does it change when inputs change?
- How will cached state be scoped — per-run, per-user, per-session, or globally?
- How will cache hits and misses be logged for observability?
Caching Layer Reference
A quick reference for production caching decisions across all four layers:
Production Readiness Checklist
Before shipping your caching architecture to production, verify each of the following:
The Mindset Shift: From Saving Calls to Freezing Decisions
The most useful reframe for caching in GenAI systems is this: you're not saving API calls. You're making explicit decisions about which parts of your agent's intelligence are stable enough to freeze, and which must remain adaptive.
A cached embedding says: "This document's semantic meaning hasn't changed." A cached tool output says: "This external state is fresh enough to act on." A cached reasoning trace says: "This decision path is deterministic from this state." Each cache entry is an architectural claim about the world.
When you see caching this way, it stops being something you add when the bill gets too high. It becomes part of how you design the system's relationship with time, state, and certainty. That's the difference between agents that occasionally work and agents that you can actually trust, evolve, and govern in production.