Most RAG pipelines fail silently. Answers look plausible, latency is acceptable, and nobody notices that retrieval quality has degraded — until a user catches a hallucination in a high-stakes context.
The fix isn't better prompting. It's measurement. And in 2026, the teams shipping reliable RAG systems share one habit: they evaluate continuously, across retrieval and generation, with metrics that actually connect to production outcomes.
This guide covers the metrics that matter, how they interact, and what a production-grade evaluation setup looks like.
Why RAG Evaluation Is Different From Standard LLM Evaluation
Standard LLM evaluation asks: did the model answer correctly? RAG evaluation asks two separate questions:
- Did the retriever surface the right context?
- Did the generator use that context faithfully?
These can fail independently.
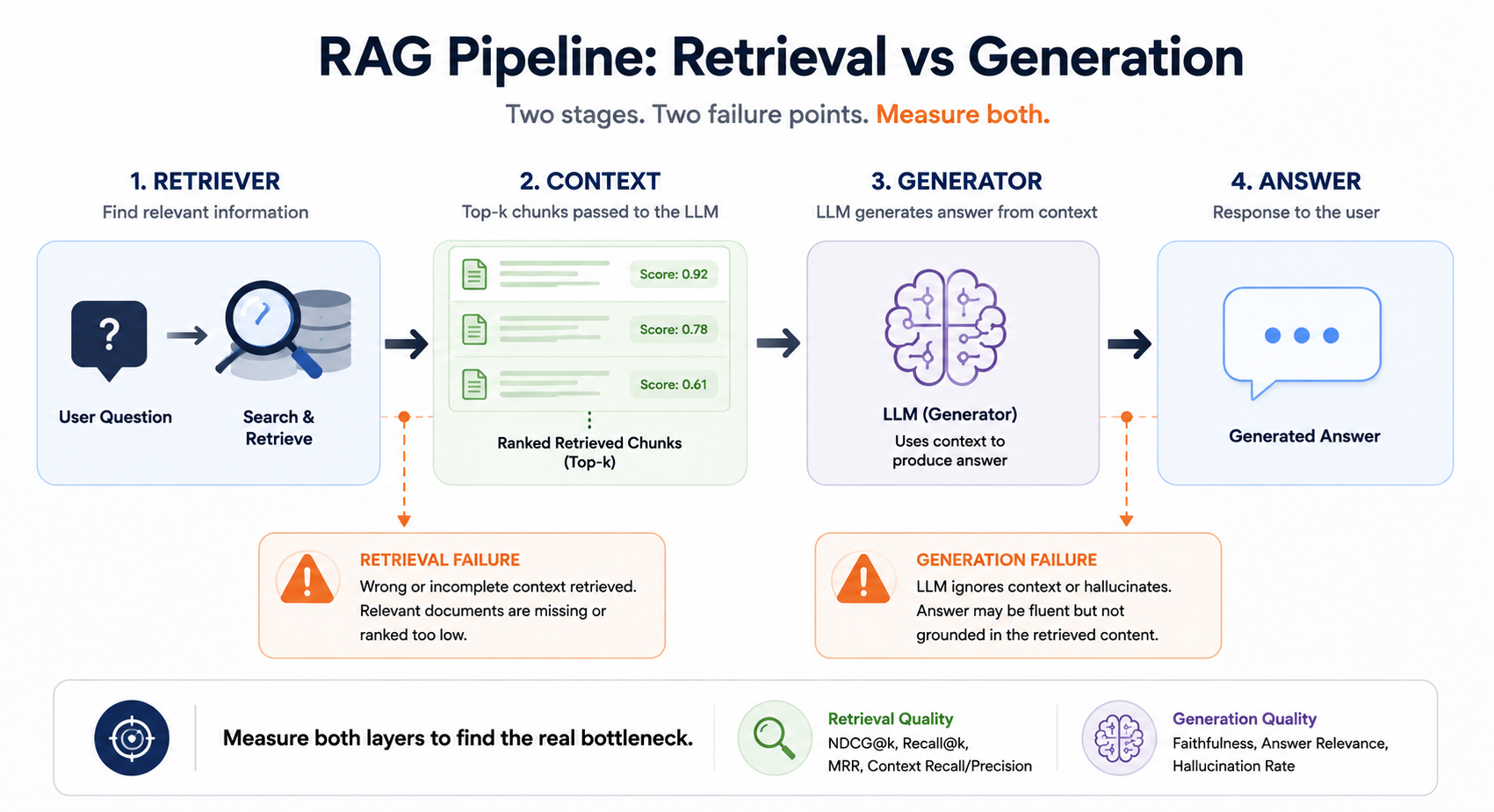
A strong retriever paired with a poorly-tuned generator will hallucinate even with good context in the prompt. A strong generator given poor retrieval will confidently fabricate. You need metrics for both layers — and you need them to be legible enough to tell you which layer broke.
Retrieval Metrics
Recall@k
Recall@k measures how many of the relevant documents appear anywhere in your top-k results, regardless of rank. Use it when completeness matters more than order — evidence retrieval, compliance workflows, knowledge-intensive QA.
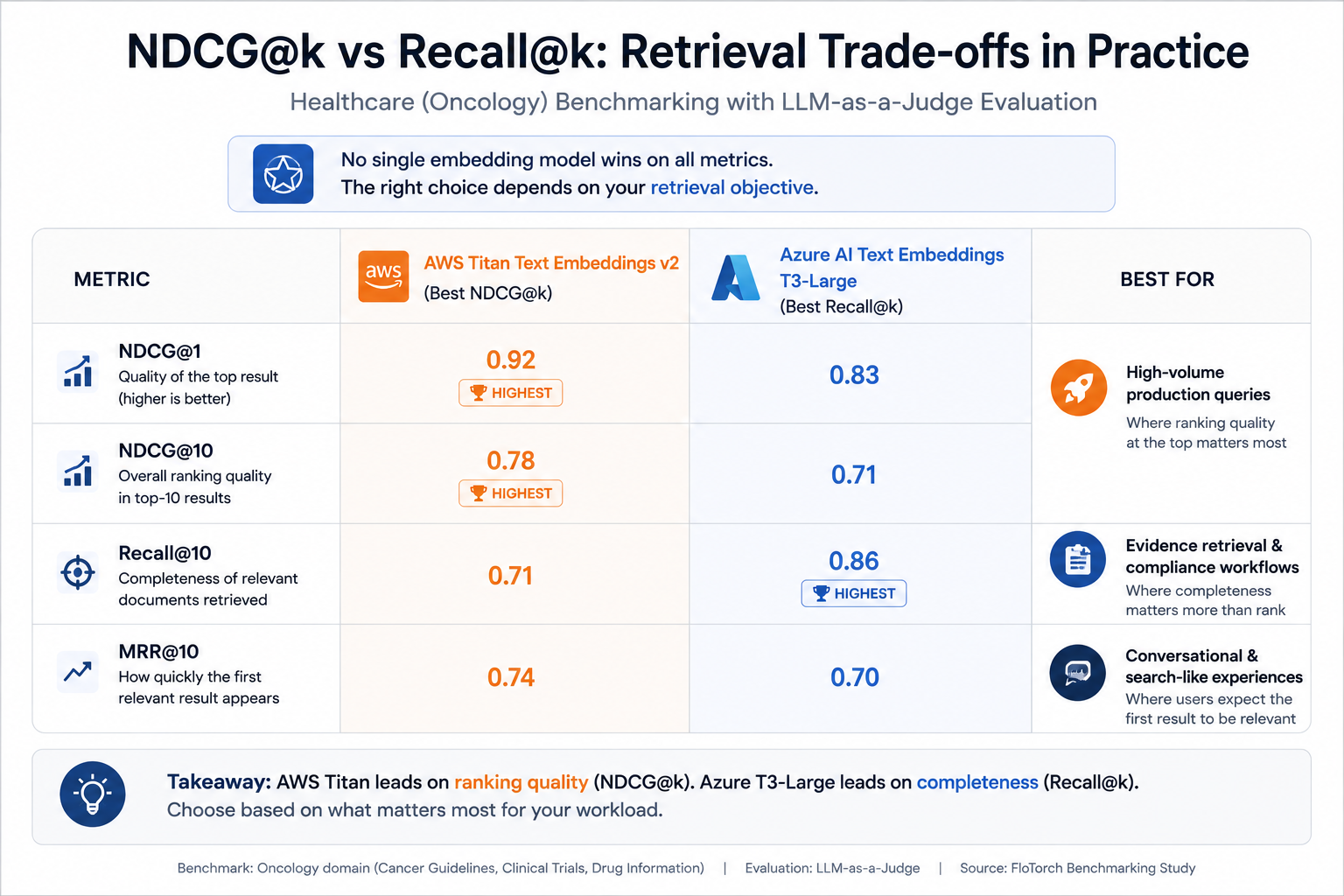
Recall@k is a core metric in FloTorch's evaluation framework. In FloTorch's healthcare benchmarking study, Azure T3-Large led on recall, making it the recommended stack for evidence-heavy workloads despite higher cost and latency. AWS Titan led on ranking quality, making it the better choice for high-volume production queries.
This is the core insight practitioners often miss: no single embedding model wins on all metrics. The right choice depends on your retrieval objective.
NDCG@k (Normalized Discounted Cumulative Gain)
NDCG@k measures the quality of your ranked retrieval results — not just whether relevant documents appear, but whether they appear early. A relevant chunk ranked 1st contributes more than the same chunk ranked 5th. It is the right metric when document order matters: question-answering systems, clinical retrieval, legal search.
When FloTorch benchmarked 7 embedding models for a leading oncology center — with no ground truth dataset available — ranking quality was a primary focus. A single normalization intervention (canonical Unicode standardization) improved ranking scores by up to +40 points across Azure and open-source models, without any model changes.
Note: NDCG@k is referenced in FloTorch's published benchmarking research but is not currently a built-in metric in the FloTorch platform console. If ranking quality evaluation is a priority for your deployment, ask the FloTorch team about integrating custom evaluation metrics.
Generation Metrics
Faithfulness
Faithfulness measures whether the generated answer is grounded in the retrieved context — not whether it's true, but whether it's supported by the documents provided. High faithfulness with low accuracy usually means your retrieval is the problem. Low faithfulness with good retrieval usually means your generator is hallucinating.
Faithfulness is the primary metric for detecting hallucinations in RAG systems in production.
Answer Relevance
Answer relevance measures whether the response actually addresses the question asked. A system can be highly faithful (stays within context) and still score low on relevance (answers a different question). Both matter.
Context Precision and Context Recall
Context precision measures signal-to-noise in your retrieved chunks. Context recall measures whether all the information needed to answer the question was retrieved in the first place.
Low context precision often signals a chunking strategy or retrieval tuning problem. Low context recall often signals an embedding model that doesn't generalize well to your domain.
Evaluation Without Ground Truth
One of the most common objections to rigorous RAG pipeline evaluation is that it requires labeled data — expert-annotated question-answer pairs that take weeks to produce and go stale as content evolves.
The 2026 answer to this is LLM-as-a-Judge: using a capable language model to assess retrieval quality and answer correctness, generating pseudo-ground-truth that enables fair cross-configuration comparison without manual annotation.
This approach isn't a workaround — it's the right method for domain-specific retrieval problems where traditional benchmarks offer no meaningful signal. FloTorch used LLM-as-a-Judge evaluation for the oncology center benchmarking study precisely because oncology-specific content (treatment protocols, drug interactions, clinical trial data) falls well outside the distribution of standard retrieval benchmarks.
Used correctly, LLM-as-a-Judge enables:
- Consistent evaluation across model and infrastructure configurations
- Rapid iteration during development without annotation bottlenecks
- Fair comparison when migrating to new embedding models or retrieval stacks
The key constraint: the judge model should be evaluated for calibration in your domain before you treat its outputs as ground truth.
The Metrics Most Teams Skip (And Shouldn't)
Cost per 1M queries
Retrieval is not free, and the cost differences between embedding providers are significant. In a production RAG system handling millions of queries, per-token embedding costs become a real line item. FloTorch's healthcare benchmarking found AWS Titan at $0.00002/1k tokens versus Azure T3-Large at $0.000143/1k tokens — a 7x difference that compounds at production scale.
If you're not tracking cost per query as part of your RAG evaluation framework, you're flying blind on a major production variable.
Average latency
Latency is a UX metric, not just an infrastructure metric. In the same benchmarking study, AWS averaged 60–85ms vs. Azure's 110–150ms — a 40% difference that directly affects user experience in real-time applications. Your RAG evaluation pipeline should surface per-configuration latency, not just accuracy.
Accuracy under domain-specific conditions
Standard benchmarks rarely reflect the distribution of queries in your actual application. The FinanceBench benchmarking report FloTorch published showed that chunking strategy alone drives dramatic accuracy differences: semantic chunking with metadata filtering reached 60% average accuracy versus 25% for fixed chunking with metadata — on the same underlying models.

Dataset-specific evaluation matters.
What a Production Evaluation Setup Looks Like
A complete RAG evaluation framework covers four layers:
1. Retrieval evaluation — Recall@k across embedding model and infrastructure configurations, with canonical normalization enforced before scoring.
2. Generation evaluation — Faithfulness, answer relevance, context precision and context recall. LLM-as-a-Judge when ground truth is unavailable.
3. Cost and latency profiling — Cost per query and average latency tracked per configuration, not just in aggregate.
4. Regression testing — Baseline metrics captured before any change to chunking strategy, embedding model, or retrieval stack, so configuration changes have measurable before/after comparisons.
The teams that catch retrieval degradation early are the ones running RAG evaluation as a continuous pipeline, not as a pre-launch checklist.
Evaluation Is Infrastructure, Not a One-Time Study
The hardest part of RAG evaluation isn't knowing which metrics to use. It's building the infrastructure to run them reliably — against your own data, across model configurations, with results that stay interpretable as your system evolves.
FloTorch provides a benchmarking and evaluation framework built for this: multi-model evaluation across retrieval and generation, LLM-as-a-Judge support, real-time cost and latency dashboards, and reproducible study frameworks that don't require starting from scratch with every model update.