The Ops Problem No One Talks About Enough
You've picked your model. You've built your prototype. Your RAG pipeline is working in a sandbox. And then comes the hard part — getting it to production in a way that's reliable, cost-efficient, and doesn't fall apart the moment real users show up.
This is where the "Ops" layer matters. And increasingly, teams are encountering two terms: LLMOps and FMOps. They sound similar. They're often used interchangeably. But they're not the same thing — and understanding the distinction is becoming important for anyone building enterprise AI systems at scale.
What is LLMOps?
LLMOps — short for Large Language Model Operations — refers to the set of practices, tools, and workflows designed to manage the lifecycle of large language models in production. Think of it as MLOps, but purpose-built for the unique demands of LLMs.
Where traditional MLOps deals with training pipelines, model versioning, and prediction serving, LLMOps layers in concerns that are specific to generative AI:
- Prompt management — versioning, testing, and optimizing prompts across model iterations
- Evaluation and benchmarking — measuring output quality across accuracy, fluency, and factual grounding
- Cost and latency monitoring — tracking token usage, inference costs, and response times in real time
- RAG pipeline management — retrieval configuration, embedding selection, chunking strategy
- Guardrails and safety — filtering harmful outputs, enforcing content policies
LLMOps is fundamentally about operationalizing a specific class of model — the large language model — and making sure it behaves predictably and cost-efficiently in production.
What LLMOps Looks Like in Practice
Most production LLM systems rely on two parallel strategies working in concert. Understanding both is key to understanding why LLMOps is more complex than it first appears.
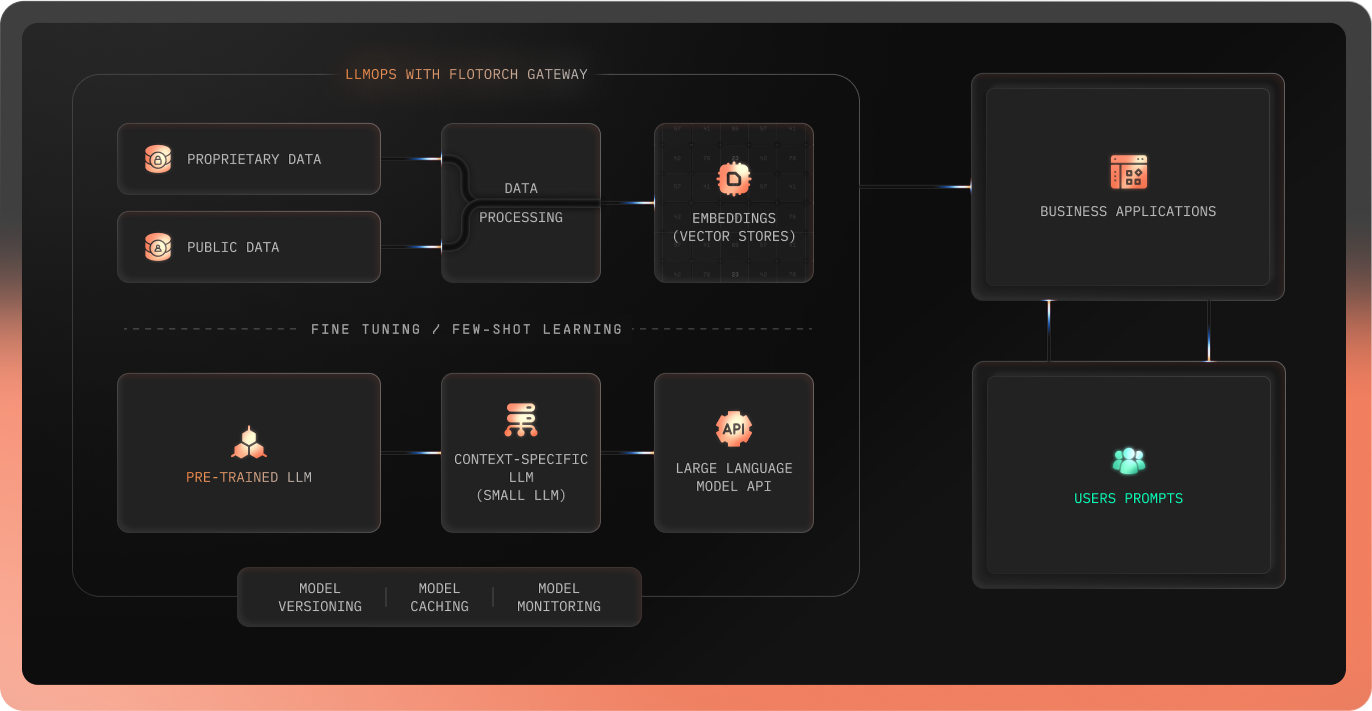
Track 1 — Retrieval Augmentation
Your models are only as good as the context they retrieve. The retrieval track processes both proprietary and public data through a structured pipeline — chunking, embedding, and indexing into vector stores — so the LLM API receives relevant, grounded context rather than relying solely on what it learned during training.
Every decision in this track has a cost implication: which embedding model you choose, how you chunk your documents, which vector store you index into, and how you balance retrieval accuracy against query latency. These are the "cost-oriented challenges" the diagram flags — and they compound quickly at production scale.
Track 2 — Model Adaptation
Not every task needs a frontier model. The model adaptation track enables fine-tuning and few-shot learning pipelines that adapt pre-trained LLMs into smaller, context-specific models — delivering better performance on domain-specific workloads at a fraction of the inference cost of running a full-scale LLM for every query.
The decision of when to fine-tune versus when to use few-shot prompting versus when to use a full frontier model is one of the core judgment calls in LLMOps — and it's one that should be data-driven, not intuitive.
The Infrastructure Layer
Beneath both tracks sits the operational foundation that teams typically build by hand — and get wrong under production load:
- Model Versioning — tracking every model configuration across experiments so you can roll back when performance drifts.
- Model Routing — Route input prompts to different models based on fallback, roundrobin, weighted or smart routine options.
- Model Caching — semantic caching that reduces redundant inference calls, cutting costs without changing application logic.
- Model Monitoring — real-time visibility into latency, token usage, error rates, and cost across every model in the stack.
These four components are what separate a working LLM prototype from a production-grade system. Skip them, and you lose visibility, control, and the ability to improve systematically.
What is FMOps?
FMOps — Foundation Model Operations — is a broader operational framework that extends beyond LLMs to cover the full landscape of foundation models an enterprise might deploy.
Foundation models include:
- Large language models (GPT-4o, Claude, Llama, Amazon Nova)
- Embedding models (Titan, Cohere Embed, text-embedding-3-large)
- Multimodal models (vision, audio, image generation)
- Domain-specific fine-tuned models (medical, legal, financial)
- Custom and open-source models running on your own infrastructure
FMOps asks a more fundamental question: How do you systematically govern, evaluate, and optimize any foundation model — regardless of modality, provider, or deployment environment?
Where LLMOps is model-class-specific, FMOps is model-class-agnostic. It's the operational framework for teams that aren't just using one type of model, but are running experiments across multiple providers, modalities, and deployment targets simultaneously.
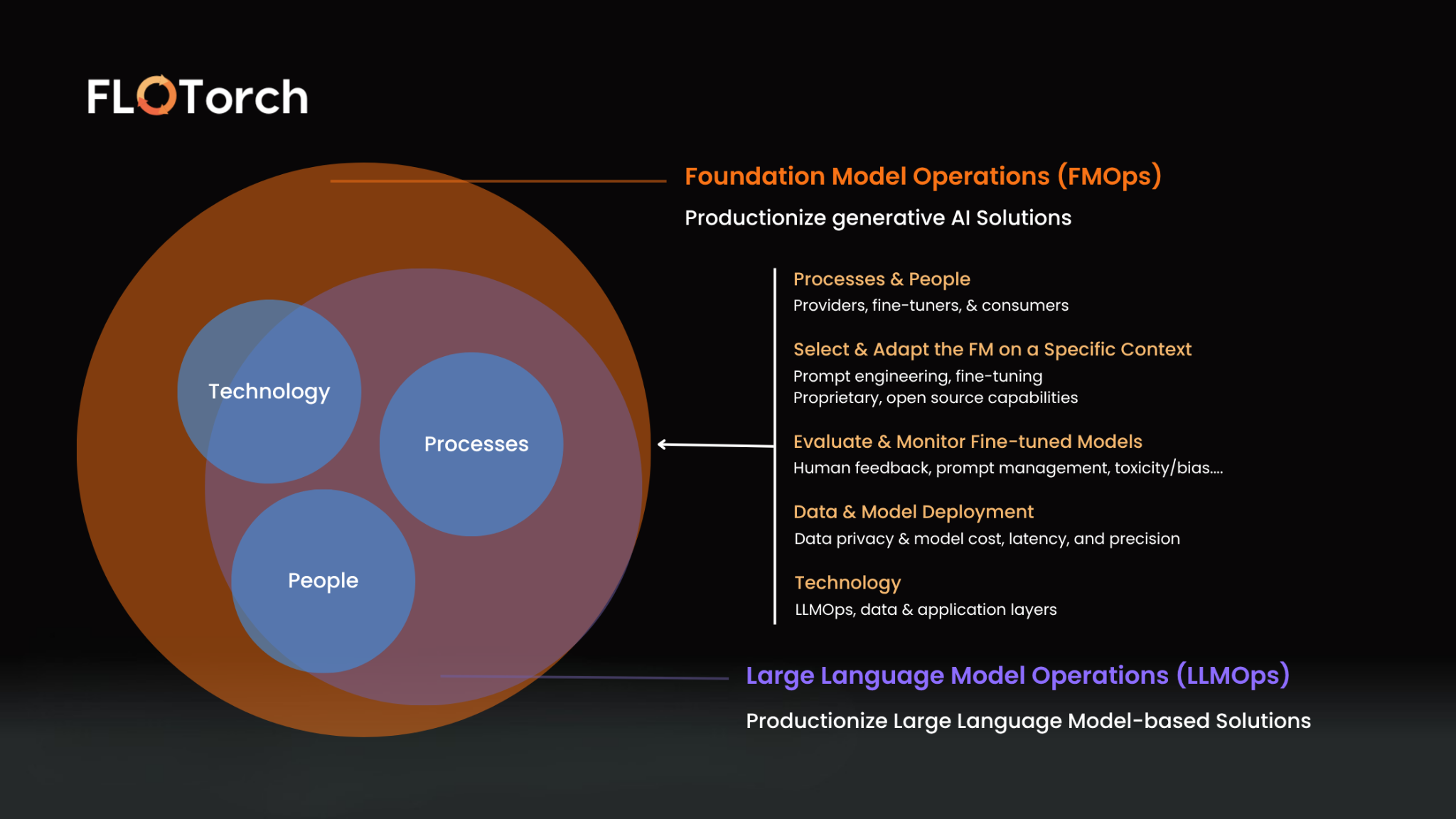
FMOps vs LLMOps: Key Differences
The practical takeaway: LLMOps is a subset of FMOps. Every team doing FMOps is implicitly doing LLMOps — but the reverse isn't necessarily true.
Why FMOps Is Becoming the Right Frame for Enterprise AI
Most enterprise AI programs don't stay monolithic for long. What starts as a single chatbot use case quickly expands — a legal team wants document automation, a finance team wants earnings analysis, a product team wants a recommendation engine. Each use case may require a different model, a different retrieval strategy, or a different cloud provider.
At this point, managing each deployment in isolation creates compounding problems:
- Cost visibility disappears — you lose sight of which model or workflow is burning a budget.
- Evaluation becomes inconsistent — different teams use different standards to measure quality.
- Switching costs spike — changing a model or provider requires significant rework.
- Security and governance fracture — no unified access control or audit trail across workloads.
FMOps solves this by introducing a unified operational layer, a consistent way to evaluate, govern, monitor, and optimize any foundation model, regardless of what it does or where it runs.
The Three Pillars of FMOps
1. Cross-Model Benchmarking
FMOps requires the ability to run structured experiments across models comparing accuracy, latency, and cost under the same conditions. This means not just testing one LLM, but running the same workload across multiple model families (say, Amazon Nova Pro vs. GPT-4o vs. Claude Sonnet) and making data-backed decisions about which model fits which task.
This applies equally to the retrieval track: which embedding model produces better semantic ranking for your specific domain? Which chunking strategy improves recall without inflating your vector storage costs? These are benchmarking questions that need structured answers, not guesswork.
2. Unified Observability
In an FMOps framework, observability isn't just about one model's token usage. It spans every model in your estate including embedding models, re-rankers, and fine-tuned variants giving teams a single view of cost, latency, error rates, and usage patterns across all AI workloads.
Model versioning and caching sit inside this pillar too. Without them, you can't attribute cost to specific configurations, and you can't trace performance changes back to the exact model or prompt version that caused them.
3. Governance and Vendor Independence
FMOps requires the ability to swap models without rewiring your entire application. This means abstracting model access behind a unified endpoint layer, enforcing consistent guardrails and access policies across providers, and avoiding hard dependencies on any single vendor's ecosystem.
The two-track architecture, retrieval and model adaptation makes this particularly important. If your retrieval stack is tightly coupled to one cloud provider's vector store, and your model layer is locked to one LLM family, you've created brittleness at every layer of the stack.
How FloTorch Supports Both LLMOps and FMOps
FloTorch is purpose-built for teams operating at this intersection. Its LLMOps and FMOps optimization layer automates evaluation across hyperparameters, benchmarking accuracy, fluency, cost, and speed while the Unified Gateway abstracts model access behind a single endpoint, making it straightforward to route traffic across LLMs, embedding models, and custom deployments without changing existing workflows.
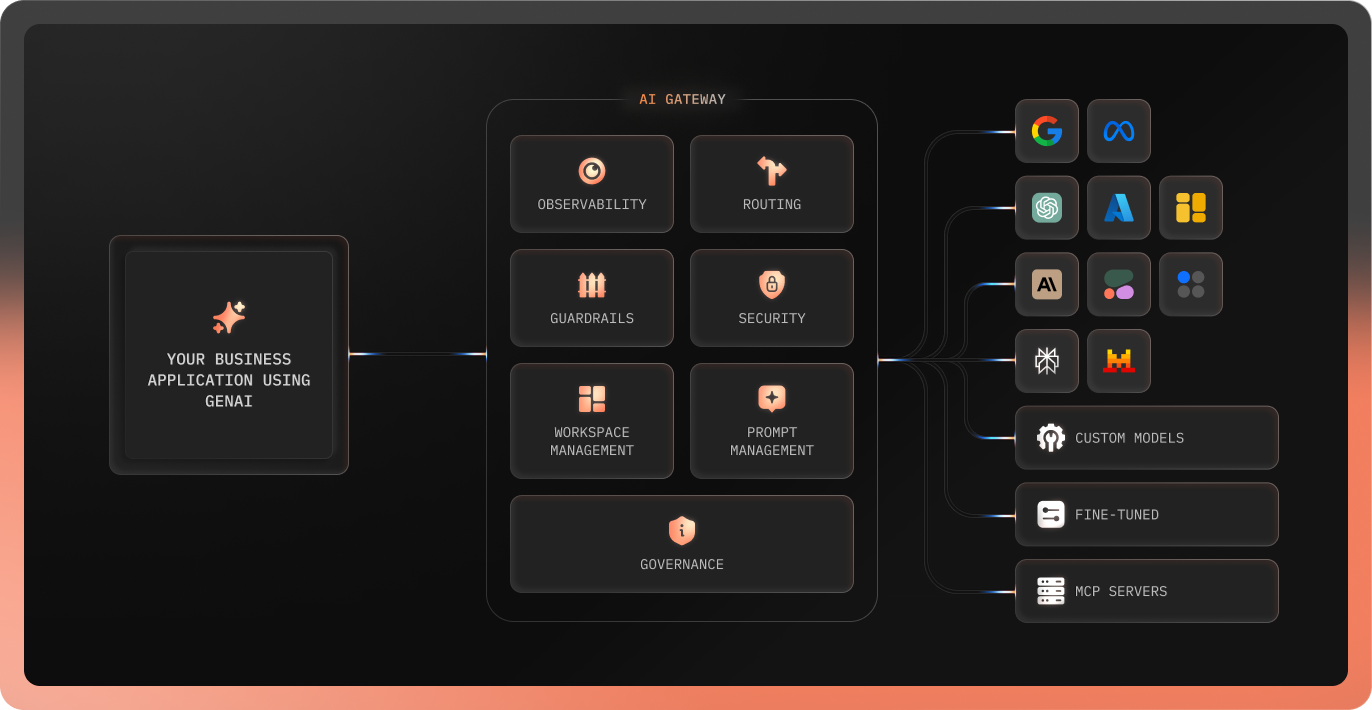
Across both the retrieval and model adaptation tracks, FloTorch handles the operational infrastructure that teams typically build by hand:
Retrieval Track: Data processing pipelines, embedding model evaluation, vector store configuration, and retrieval accuracy benchmarking, all configurable without code changes and testable across providers in parallel.
Model Adaptation Track: Fine-tuning pipelines, few-shot learning configuration, hyperparameter search, and domain-specific accuracy benchmarking, so the decision of which model to run for which task is driven by data, not assumption.
Infrastructure Layer: Model versioning tracks every configuration across experiments. Semantic caching cuts redundant inference costs. Real-time monitoring surfaces latency, token usage, and error rates across every model in the stack, giving teams the visibility to optimize continuously rather than react after something breaks.
In practice, this means:
- Benchmark any model, any provider — run structured comparisons across AWS, Azure, and open-source models using consistent evaluation criteria.
- Plug and play without lock-in — switch models seamlessly without workflow rewrites.
- Full observability out of the box — track latency, token usage, cost, and errors with live dashboards and full traceability.
- Governance at scale — RBAC, audit logs, API rate limiting, and secure hosting across cloud environments.
Which One Do You Need?
If you're running one LLM for one use case and optimizing prompts and costs for that specific workflow, LLMOps covers your needs, and the two-track architecture described above gives you a practical template for how to think about your retrieval and model layers.
If you're scaling across multiple AI use cases, evaluating models across providers, or building a platform that multiple teams will use, FMOps is the right operational frame. And you'll want infrastructure that supports both without requiring you to manage them separately.
The good news is that the distinction doesn't require you to build two separate systems. It requires an operational layer that is flexible enough to handle the full foundation model landscape, one that grows with your AI program, rather than becoming a bottleneck.
FloTorch is an enterprise platform designed to build, deploy, and scale agentic workflows with built-in LLMOps and FMOps capabilities for benchmarking, observability, and intelligent routing. Available on AWS Marketplace and GitHub.