.png)
In 2026, Retrieval-Augmented Generation (RAG) has become the backbone of enterprise AI systems — powering internal copilots, financial research assistants, customer intelligence engines, knowledge management platforms, and compliance automation.
Yet despite widespread adoption, organizations continue to see wildly inconsistent RAG outcomes.
The same model, running similar workloads, can behave reliably in one enterprise and unpredictably in another.
The reason is clear:
RAG success is no longer defined by the large language model — but by the performance of the entire retrieval pipeline.
And this is exactly what the latest enterprise evaluations and FloTorch’s own benchmarking work (across datasets like CRAG and FinanceBench) reveal. The real performance gains come from retrieval quality, chunking strategy, re-ranking, vector database configuration, and cost-aware model selection — not solely from model size.
This report breaks down the 2026 RAG performance landscape for CTOs, CIOs, and product leaders planning their next wave of AI investment.
1. The Shift to Evaluation-Driven RAG
RAG has evolved from “retrieve → generate” to a multi-stage, evaluation-driven system that must be optimized and measured holistically.
The enterprises leading in 2026 have adopted a shared understanding:
RAG performance = (Retrieval Quality × Chunking × Re-Ranking × Model Routing) / Cost
In this formula:
- Retrieval determines what the model sees.
- Chunking determines how it sees it.
- Re-ranking controls signal-to-noise ratio
- Model routing balances accuracy vs. cost
- Observability ensures long-term governance.
In 2026, RAG is no longer a model problem — it is a retrieval engineering problem.
2. Retrieval Quality Is the Primary Driver of RAG Accuracy
Across enterprise workloads and FloTorch’s structured evaluations, the biggest revelation is this:
Most RAG errors originate from the retrieval layer, not the LLM.
Patterns consistently show:
- Irrelevant or noisy context → hallucinations
- Missing context → incomplete answers
- Over-retrieval → reduced grounding
- Weak chunk boundaries → lower recall
Hybrid retrieval — combining dense embeddings with BM25-style keyword matching — continues to outperform dense-only search across most enterprise document types, especially:
- finance & audit reports
- legal contracts
- policy documents
- manufacturing SOPs
- regulatory guidelines
Hybrid search captures exact terms, numbers, acronyms, and structured language that dense embeddings often miss.
Enterprises that default to hybrid retrieval report 20–40% higher retrieval recall in benchmarked scenarios.
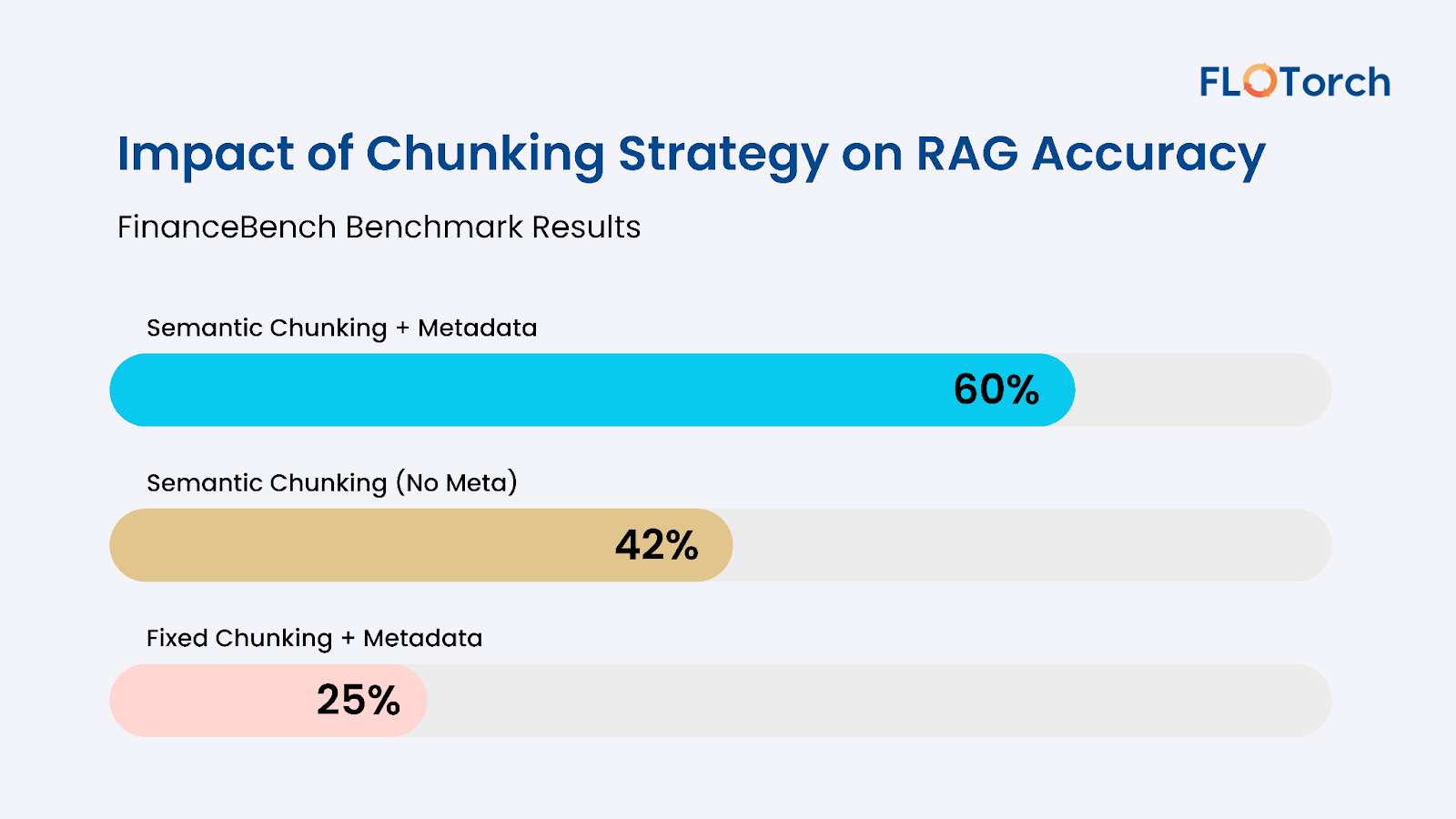
3. Chunking Strategy Can Shift Accuracy by Over 60%
One of the most striking insights from FloTorch’s FinanceBench evaluations is the impact of chunk segmentation on RAG accuracy:
- Semantic chunking + metadata filtering: 60%
- Semantic chunking (no metadata): 42%
- Fixed chunking + metadata: 25%
Enterprises often underestimate chunking, treating it as a developer-level detail. In practice, chunking has emerged as a strategic performance lever.
High-performing RAG systems follow a consistent pattern:
- Chunk boundaries align with document structure
- Overlap (typically 12–20%) preserves semantic continuity
- Metadata filtering removes noise such as headers, disclaimers, and repeated templates
In financial, compliance, and technical corpora, semantic chunking is now mandatory for production-grade RAG.
4. Re-Ranking Delivers the Largest Single Accuracy Improvement
If retrieval decides what is retrieved, re-ranking decides what the model actually sees.
Enterprise benchmarks show:
- Cross-encoder re-ranking improves precision by 18–42%
- Hallucinations drop significantly when irrelevant context is removed.
- High-quality top-3/top-5 passages correlate strongly with grounded answers.
Re-ranking has overtaken LLM size as the dominant performance accelerator.
In other words:
Improving your re-ranker yields more ROI than upgrading your model.
This is especially visible in multi-document workflows such as:
- research copilots
- financial Q&A
- HR policy assistants
- audit document summaries
5. Which LLMs Actually Perform Best for RAG?
The question executives ask most often:
“Which model should we standardize on?”
Benchmarking over the past year reveals a more nuanced truth: the best model depends on data type, cost objectives, and retrieval strength.
Here’s what enterprise leaders need to know:
GPT-4o / GPT-5 Family
Strength: Best for deep reasoning, unstructured text, and multi-hop RAG.
Ideal for: Knowledge synthesis, research assistants, cross-document Q&A.
Tradeoff: Higher cost; unnecessary for most retrieval-first tasks.
Claude 3.7 (Sonnet / Opus)
Strength: Lowest hallucination rate; excellent grounding.
Ideal for: Compliance, policy, legal, risk, and regulated workloads.
Tradeoff: Slightly slower for complex chain-of-thought responses.
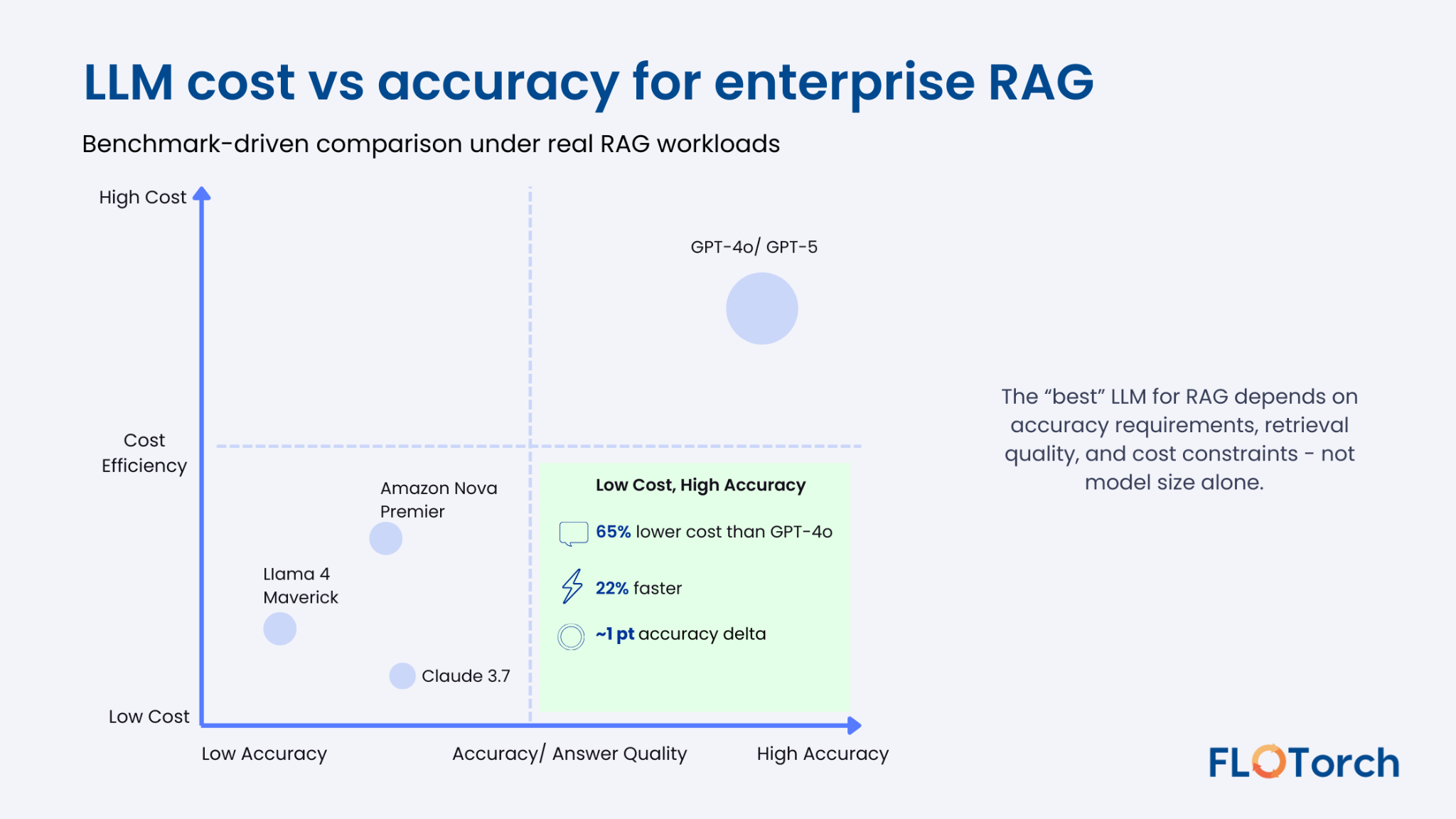
Amazon Nova Premier / Pro (FloTorch CRAG Benchmark)
FloTorch analysis showed:
- 65.26% lower cost than GPT-4o
- 21.97% faster
- Only ~1.5-point accuracy delta
Detailed benchmark results: RAG Benchmarking of Amazon Nova and GPT-4o Models
Ideal for: High-volume RAG where cost efficiency matters.
Llama 4 Maverick (FinanceBench)
A notable insight from FinanceBench:
Open-model performance is catching up faster than expected.
- Strong accuracy on structured financial data
- Very low latency
- Minimal inference cost
Financebench Benchmarking Report
Ideal for: On-prem deployments, VPC-first organizations, and financial workloads.
6. Vector Databases Matter More Than Most Enterprises Expect
In 2026, vector databases will no longer be an interchangeable infrastructure. Performance varies sharply across:
- index type (HNSW, IVF, PQ, disk-ann)
- metadata filtering
- hybrid search capabilities
- ingestion speed
- recall latency tradeoffs
FloTorch’s enterprise evaluations consistently highlight ideal fits:
- Pinecone → Best for production reliability and high recall at enterprise scale
- OpenSearch → Best for sparse + dense hybrid retrieval in compliance-heavy environments
- PGVector → Best lightweight option for teams operating under ~10M embeddings
- LanceDB → Strong fit for local-first and embedded RAG workflows
- ChromaDB → Best for prototyping and early-stage RAG experimentation
- Azure AI Search → Ideal for enterprises already standardized on Azure infrastructure
- OpenAI Vector Stores → Best for tightly coupled OpenAI-native RAG pipelines
The takeaway for leaders:
Your retrieval store must match your data type and scaling model — not the other way around.
7. What Enterprise Leaders Should Benchmark in 2026
High-performing teams benchmark RAG systems continuously across:
- Retrieval quality — dense vs hybrid recall and relevance
- Chunking effectiveness — cohesion, overlap, and metadata filtering
- Re-ranking precision — impact on hallucinations
- Cost–performance trade-offs — cost per correct answer
- Model routing efficiency — matching models to workloads
- Observability and drift — monitoring degradation over time
Enterprises that treat RAG as an evolving system, rather than a one-time implementation, achieve far more reliable outcomes.
8. Where FloTorch Fits in This Landscape
FloTorch is increasingly used by enterprise teams as their RAG evaluation and optimization layer.
It sits across the pipeline — measuring, comparing, and tuning each stage.
FloTorch helps enterprises:
- Benchmark models, retrievers, chunkers, and vector databases using consistent, repeatable metrics across datasets and workloads.
- Evaluate RAG performance end-to-end, including retrieval quality, context relevance, groundedness, hallucination rates, latency by stage, and cost per correct answer.
- Optimize RAG pipelines using techniques like semantic chunking, metadata filtering, hybrid retrieval, and cross-encoder reranking
- Implement model routing based on cost-performance tradeoffs and workload requirements.
- Monitor RAG behavior with observability dashboards covering accuracy drift, retrieval failures, and system performance over time.
- Validate accuracy and groundedness with standardized evaluation frameworks suitable for enterprise governance.
It becomes the system that helps organizations move from:
RAG experiments → Reliable, governed, scalable enterprise RAG.
9. Final Perspective for CIOs & CTOs
In 2026, RAG has crossed the threshold from “promising technique” to mission-critical enterprise architecture.
The organizations leading this shift share common traits:
- Benchmark continuously
- Optimize retrieval, not just models
- Invest in chunking and ranking.
- Adopt hybrid search by default.
- Deploy multi-model strategies
- Build observability into every stage.
RAG is no longer just about generating answers.
It is about retrieving the right information, shaping context intelligently, and ensuring reliable reasoning.
The enterprises that treat RAG as an evaluated, engineered system — rather than a feature — will lead the next decade of AI transformation.