The AI Smart Dispatcher: How FloTorch Routes Your LLM Queries for Maximum Speed, Reliability & Cost Efficiency
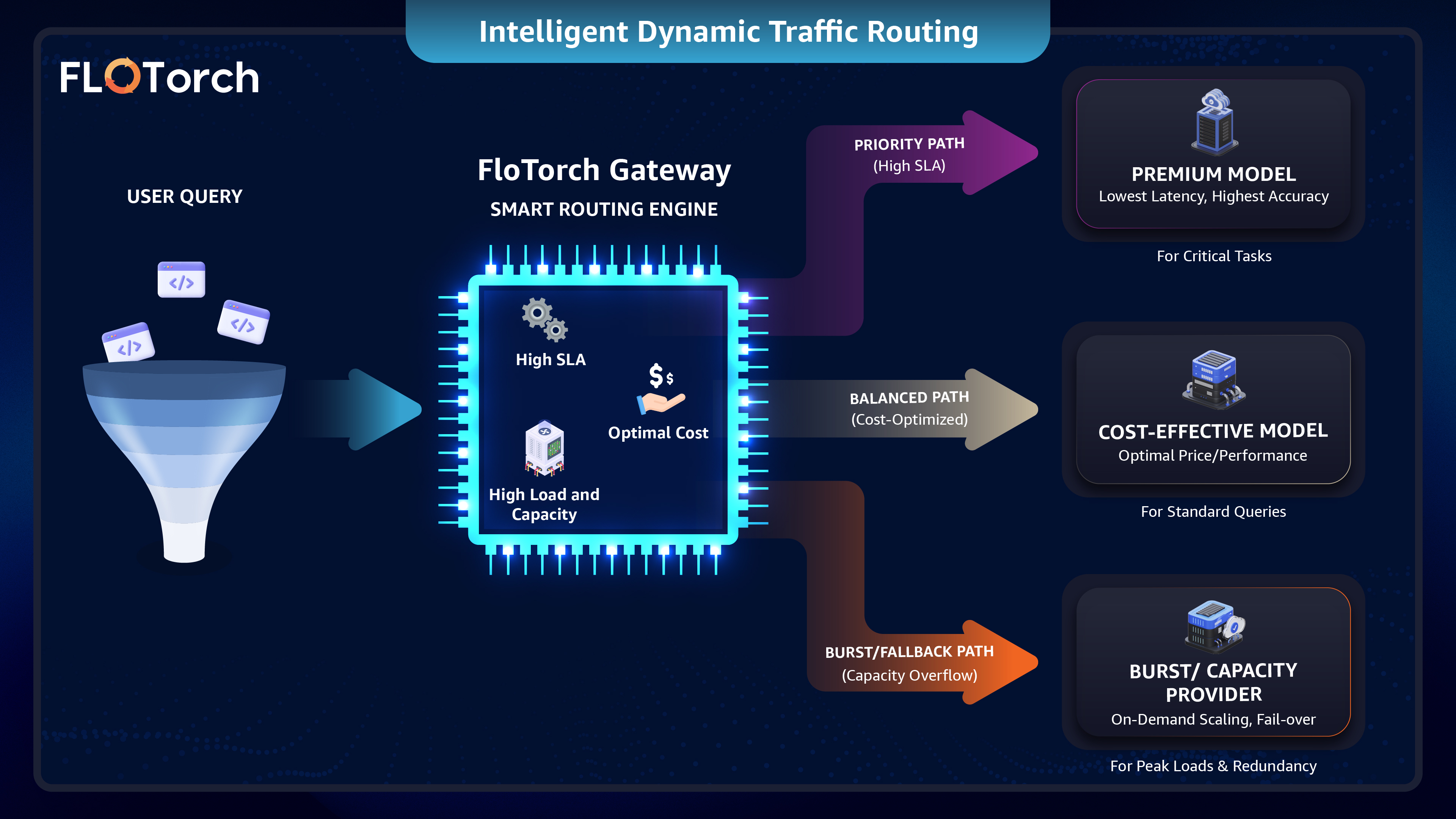
In today’s GenAI landscape, businesses are overwhelmed by choice—GPT-4o, Claude 3.5 Sonnet, Llama 3, and dozens more. Each offers different strengths in cost, speed, and specialization, but integrating and managing multiple LLMs quickly becomes a technical and financial burden. What if your AI infrastructure could automatically select the best model for each request, manage spending intelligently, and shield your application from provider outages?
That’s precisely what FloTorch’s AI Smart Dispatcher delivers. Acting as an intelligent routing layer for your AI stack, it automatically dispatches each query to the optimal model using time-based, content-aware, budget-aware, and SLA-driven logic. The result is a more straightforward, more reliable, and dramatically more cost-efficient AI architecture. Read the full article to discover how the Smart Dispatcher transforms multi-model chaos into a streamlined, future-proof advantage for your business.
Read the full breakdown of how Smart Dispatcher brings speed, reliability, and cost efficiency to multi-model LLM systems: https://medium.com/@flotorchAI/the-ai-smart-dispatcher-how-flotorch-routes-your-llm-queries-for-maximum-speed-reliability-cost-dbf57508a6b4